Kullandığımız modelin ne kadar sağlıklı, kullanılabilir olduğunu test etmek için veri setimizi train ve test olarak iki parçaya ayırırız. Train veri seti, modelimiz tarafından kullanılır ve bir bağıntı kurar. Modelimizin ne kadar sağlıklı sonuç ürettiğini test etmek için Test setini kullanırız. Böylece modelin kullanılıp kullanılamayacağına karar vermiş oluruz. Bir başka önemli konu ise eğitim ve test verileri hangi oranda bölünmeli. Literatürde veri setinin % 70 Eğitim - % 30 Test ya da % 80 Eğitim - % 20 Test verisi olarak bölmek kabul görmüştür.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
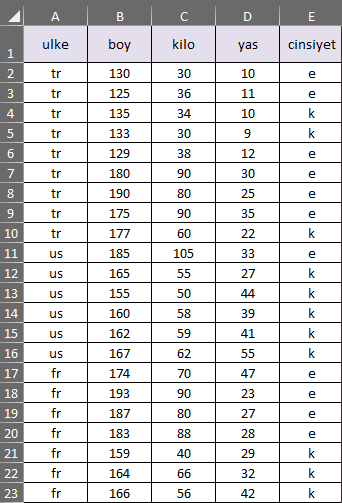
veriler= pd.read_csv("veriler.csv")
#ülke kolonu one hot encoding yapılıyor
ulke=veriler.iloc[:,0:1]#ilk kolonu alır
from sklearn.preprocessing import OneHotEncoder
ohe=OneHotEncoder(categorical_features='all')
#kolonu fit transformdan geçirip geri kolona yazsın
ulke=ohe.fit_transform(ulke).toarray()
#numpy array den dataFrame yapma(index ve kolon başlıkları eklenir)
ulke_df=pd.DataFrame(data=ulke,index=range(22),columns=['fr','tr','us'])
#print(ulke_df)
#sayisal kolonlar
sayisal_kolonlar=veriler.iloc[:,1:4].values
#numpy array den dataFrame yapma(index ve kolon başlıkları eklenir)
sayisal_kolonlar_df=pd.DataFrame(data=sayisal_kolonlar,index=range(22),columns=['boy','kilo','yas'])
#print(sayisal_kolonlar_df)
#cinsiyet
cinsiyet=veriler.iloc[:,4:5]#4 ile 5.kolon arası, 5.kolon dahil değil
#numpy array den dataFrame yapma(index ve kolon başlıkları eklenir)
cinsiyet_df=pd.DataFrame(data=cinsiyet,index=range(22),columns=['cinsiyet'])
#print(cinsiyet_df)
#BİRLEŞTİRME-CONCAT(DataFrame ler birleştirilir)
#Veriyi Geri Birleştirme, iki veri birleştirme
ulke_sayisal_kolanlar_concat=pd.concat([ulke_df,sayisal_kolonlar_df],axis=1)#axis=1 yanyana birleştirir
#TEST VE TRAIN VERİLERİ BÖLME
#ulke_sayisal_kolanlar_concat değişkeni içnde ülke,boy,kilo ve yaş kolonları var cinsiyet kolonu yok
#cinsiyet kolonu bağımlı değişken, diğer kolonlar ise bağımsız değişkenler
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(ulke_sayisal_kolanlar_concat,cinsiyet,test_size=0.33,random_state=0)
Önemli Not: Veri setiniz çok küçükse (örneğin 100-200 örnek), veriyi klasik %80 eğitim - %20 test şeklinde böldüğünüzde Test seti çok küçük kalır: Sadece 20-30 veriyle modelin gerçek performansını ölçemezsiniz. Şans eseri çok iyi veya çok kötü sonuçlar alabilirsiniz. Eğitim seti yetersiz kalır: Modelin öğrenmesi için gereken her veriye ihtiyacı vardır. Bu durumlarda K-Fold Cross Validation (K-Katlı Çapraz Doğrulama) kullanmak kesinlikle en sağlıklı yoldur. K-fold, veriyi train ve validation olarak ikiye bölmekten ziyade, verinin tamamını (veya test ayrıldıktan sonra kalan kısmını) farklı parçalara bölerek her parçanın hem eğitim hem de doğrulama aşamasında yer almasını sağlar.