K-modes algoritması: Makine öğrenmesi kümeleme işlemlerinde tüm veriler kategorik olduğunda kullanılır. K-Modes, kategorik veriler üzerinde çalışan bir kümeleme (clustering) algoritmasıdır. Makine öğrenmesinde benzer özelliklere sahip veri gruplarını keşfetmek amacıyla kullanılır ve özellikle sayısal olmayan veriler için geliştirilmiştir. K-Means algoritmasının kategorik verilere uyarlanmış bir versiyonu olarak düşünülebilir. K-Means ortalama değerler üzerinden çalışırken, K-Modes en sık görülen kategori değerlerini (mode) kullanarak kümeler oluşturur. Bu sayede cinsiyet, şehir, eğitim durumu veya ürün kategorisi gibi kategorik değişkenlerden oluşan veri setlerinde etkili sonuçlar elde edebilir. Bu yazıda K-Modes algoritmasının çalışma mantığını, avantajlarını ve Python ile nasıl uygulanacağını inceleyeceğiz.
Kategorik veri kümeleri için özelleşmiştir ve kategorik veri kümeleri üzerinde daha verimli sonuçlar verir.
K-Modes algoritmasının nasıl çalıştığını somut bir örnek üzerinden inceleyelim. Aşağıdaki veri seti, farklı kişilere ait saç rengi, göz rengi ve ten rengi bilgilerinden oluşmaktadır. Bu özelliklerin tamamı kategorik değerlerden oluştuğu için K-Means yerine K-Modes algoritmasının kullanılması daha uygundur. Makalenin geri kalanında bu veri seti üzerinden ilerleyerek verilerin nasıl dönüştürüldüğünü, kümelerin nasıl oluşturulduğunu ve algoritmanın benzer özelliklere sahip kişileri nasıl aynı grupta topladığını göreceğiz.

#importing necessary libraries
from scipy.spatial.distance import pdist, squareform
import pandas as pd # Veri manipülasyonu ve analiz için pandas kütüphanesini içe aktarıyor
import numpy as np # Sayısal işlemler için numpy kütüphanesini içe aktarıyor
# !pip install kmodes # Gerekli kütüphaneyi yüklemek için (ilk kullanımda) bu satır aktif hale getirilebilir
from kmodes.kmodes import KModes # Kategorik veri kümeleri için K-modes algoritmasını içe aktarıyor
import matplotlib.pyplot as plt # Grafikler oluşturmak için matplotlib.pyplot'u içe aktarıyor
from sklearn.preprocessing import LabelEncoder
# Grafiklerin Jupyter Notebook'ta direkt görüntülenmesini sağlıyor
%matplotlib inline
veriler=pd.read_csv(veriler_kmode.csv)
print(veriler)
# Create toy dataset
hair_color = veriler.iloc[:, 1]
eye_color = veriler.iloc[:, 2]
skin_color = veriler.iloc[:, 3]
person = veriler.iloc[:, 0]
#print(person)
data = pd.DataFrame({'person':person, 'hair_color':hair_color, 'eye_color':eye_color, 'skin_color':skin_color}) # Verileri bir DataFrame'e aktarıyor
data = data.set_index('person') # 'person' sütununu DataFrame'in indeksine ayarlıyor
print(data) # DataFrame'i ekrana yazdırıyor
# pdist fonksiyonu kategorik veri ile çalışmadığı için kategorik verileri sayısal değerlere dönüştürüyoruz,
le = LabelEncoder() # LabelEncoder nesnesi oluşturuyoruz
for col in data.columns:
data[col] = le.fit_transform(data[col]) # Her kategorik sütunu sayısal değerlere dönüştürüyoruz
# Kategorik veriler üzerinde Hamming mesafe matrisini oluşturuyoruz
# Her iki satır arasındaki hamming mesafesini ölçüyoruz
hamming_distances = pdist(data.values, metric='hamming') # Hamming mesafelerini vektör olarak hesaplar
hamming_matrix = squareform(hamming_distances) # Vektörü kare matris formuna çevirir
# Hamming mesafe matrisini bir DataFrame olarak düzenliyoruz
hamming_df = pd.DataFrame(hamming_matrix, index=data.index, columns=data.index)
print(hamming_df)
# Elbow curve to find optimal K
cost = [] # Farklı küme sayılarının maliyetlerini saklamak için boş bir liste oluşturuyor
K = range(1,5) # Küme sayısını 1'den 4'e kadar denemek için bir aralık belirliyor
for num_clusters in list(K): # Her küme sayısı için döngü başlatıyor
kmode = KModes(n_clusters=num_clusters, init="random", n_init=5, verbose=1) # K-modes algoritmasını, belirtilen küme sayısı ve rastgele başlangıçla tanımlıyor
kmode.fit_predict(data) # K-modes algoritmasını veri üzerinde çalıştırarak kümeleri oluşturuyor
cost.append(kmode.cost_) # Her küme sayısı için maliyeti (inertia) 'cost' listesine ekliyor
plt.plot(K, cost, 'bx-') # Küme sayısına karşılık gelen maliyet değerlerini grafikle gösteriyor
plt.xlabel('No. of clusters') # X eksenine 'No. of clusters' etiketini ekliyor
plt.ylabel('Cost') # Y eksenine 'Cost' etiketini ekliyor
plt.title('Elbow Method For Optimal k') # Grafiğe başlık ekliyor
plt.show() # Grafiği görüntülüyor
# Assign clusters to each row
clusters = kmode.fit_predict(data) # Her satır için küme etiketlerini alıyoruz
data['Cluster'] = clusters # 'Cluster' adlı yeni bir sütun olarak DataFrame'e ekliyoruz
print("uğruna talan olsun vay servetim külli varım:", clusters)
# Display the data with cluster assignments
print(data) # Her satırın ait olduğu kümeyi gösteren tabloyu ekrana yazdırıyoruz
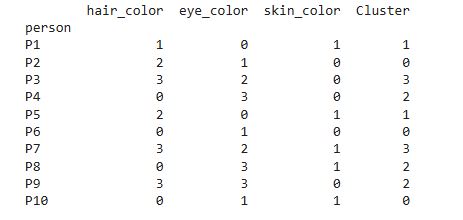
Yukarıdaki sonuçlar, K-Modes algoritmasının kategorik özelliklere sahip bireyleri benzerliklerine göre kümelere ayırdığını göstermektedir. Veri setinde her kişinin saç rengi (hair_color), göz rengi (eye_color) ve ten rengi (skin_color) bilgileri sayısal kodlarla temsil edilmiştir. K-Modes algoritması bu kategorik değerler arasındaki benzerlikleri analiz ederek kişileri dört farklı kümeye (Cluster 0, 1, 2 ve 3) ayırmıştır. Örneğin P1 ve P5 aynı kümeye atanırken, P3 ve P7 başka bir kümede yer almaktadır. Bunun nedeni, aynı küme içerisindeki bireylerin kategorik özelliklerinin birbirine daha çok benzemesidir. Böylece veri setindeki benzer gözlem grupları otomatik olarak keşfedilmiş ve veri içerisindeki gizli yapı ortaya çıkarılmıştır.