Makine öğrenmesinde t-SNE (açılımı: t-Distributed Stochastic Neighbor Embedding) yüksek boyutlu verileri 2D veya 3D gibi daha düşük boyutlara indirgemek için kullanılan, özellikle veri görselleştirme amacıyla tercih edilen güçlü bir boyut indirgeme yöntemidir. t-SNE, 2008 yılında Laurens van der Maaten ve Geoffrey Hinton tarafından geliştirilmiş bir algoritmadır.
Nasıl Çalışır?
- Yüksek boyutlu uzayda her bir veri noktası etrafında bir olasılık dağılımı oluşturulur (yakın komşulara yüksek olasılık verilir).
- Bu benzerlik bilgisi çiftler arasındaki benzerlik ölçüleri olarak tutulur.
- Daha sonra, düşük boyutlu bir uzayda (örneğin 2D) benzer bir dağılım oluşturulmaya çalışılır.
- Aradaki farkı minimize etmek için Kullback-Leibler divergence (KL divergence) adı verilen bir maliyet fonksiyonu kullanılır.
- Bu maliyet fonksiyonu, benzerlik yapılarını koruyacak şekilde düşük boyutlu yerleştirme yapar.
Neden Kullanılır?
- Yüksek boyutlu verilerin (örneğin 50, 100, 300 boyutlu) daha iyi anlaşılması ve görselleştirilmesi için.
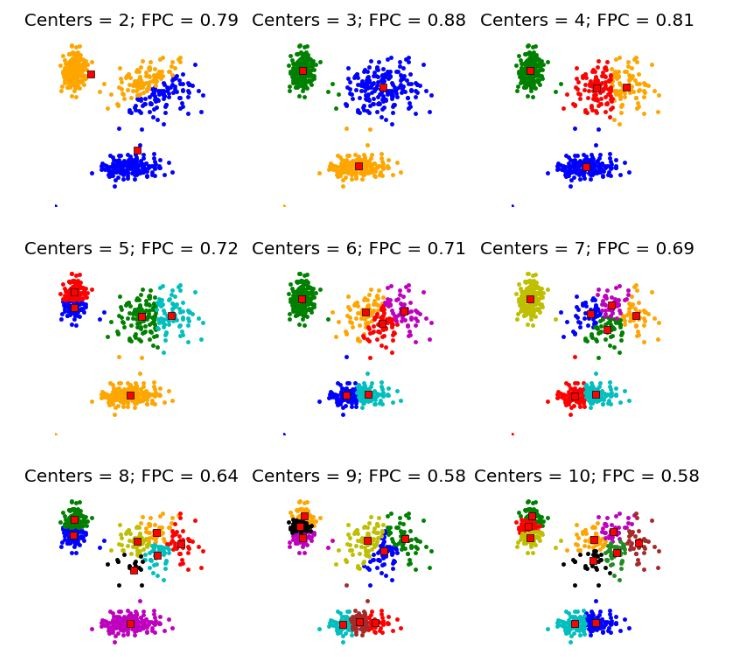
- Kümeleme sonuçlarını 2 boyutlu grafikle yorumlamak için.
- Görselleştirme yoluyla anlamlı yapılar, gruplar, anomaliler veya aykırı değerleri tespit etmek için.
Nerelerde Kullanılır?
- Görüntü sınıflandırma sonrası özellik haritalarını incelemek (örneğin CNN son katman çıkışları)
- Doğal dil işleme (NLP) çalışmalarında kelime gömme (word embedding) vektörlerini görselleştirmek
- K-means, DBSCAN, GMM gibi kümeleme yöntemlerinin sonuçlarını anlamak
- Anomali tespiti için görsel analiz
Özetle: t-SNE, yüksek boyutlu verilerin düşük boyutlu uzayda görselleştirilmesi için kullanılan, benzerlikleri korumaya çalışan güçlü bir non-lineer boyut indirgeme algoritmasıdır.
PCA vs t-SNE: Temel Farklar
| Özellik | PCA | t-SNE |
|---|---|---|
| Amaç | Boyut indirirken varyansı korumak | Boyut indirirken benzerlik yapısını korumak |
| Tür | Doğrusal (Linear) boyut indirgeme | Doğrusal olmayan (Non-linear) boyut indirgeme |
| Yöntem | Özdeğer (eigenvalue) ve özvektör (eigenvector) analizi | Olasılıklı komşuluk benzerliği ve KL divergence minimizasyonu |
| Çıkış | Bileşenler orijinal verinin lineer birleşimi | Yeni bir uzayda göreli benzerliklere göre konumlandırma |
| Hız | Çok hızlı, büyük verilerde bile kolayca çalışır | Yavaş, özellikle büyük veri kümelerinde maliyetli |
| Tutarlılık | Sonuçlar tekrar edilebilir, kararlıdır | Sonuçlar rastgele başlatmaya göre değişebilir |
| Uygulama | Veri ön işleme, modelleme öncesi boyut indirgeme | Veri görselleştirme için en uygun yöntem |
| Yorumlanabilirlik | Bileşenler yorumlanabilir (PC1: en çok varyans vs.) | Bileşenler yorumlanamaz (görsellik amaçlı) |
Ne zaman hangisini kullanmalı?
Veri görselleştirme ve veri içi gizli kümeleri keşfetmek için t-SNE kullanılır. Model eğitimi öncesi boyut indirgeme ve Bileşenleri yorumlamak istiyorsan PCA kullanabilirsin.
UMAP
Kaynaklar
- https://www.instagram.com/p/DZvB_ZBl5-F/?igsh=MXBndjVoc2luMm4zYw%3D%3D